はじめに
AWSに直接接続できないオンプレミスのOracle DatabaseをRDSに移行することになりました。
この場合、RDSにデータファイルをアップロードしてOracle Data Pumpでインポートする方法がありますが、Amazon EC2に一旦データファイルをアップロードした後、PL/SQLのUTL_FILEパッケージを使ってRDSのディスクにアップロードという流れになり、作業が煩雑だなと感じていました。
AWSのサービスを活用して実現できないものかと調べていたところ、「Amazon RDS for Oracle が Amazon S3との統合によるデータ送受信機能のサポートを開始」という記事から、RDSからS3に格納しているファイルを直接ダウンロードできる機能が実装されていることが分かりました。タイミングよく実装された機能ですので、今回はこの機能を使用してデータ移行を行い、その手順についてご紹介したいと思います。
環境について
今回使用した環境は以下の通りです。
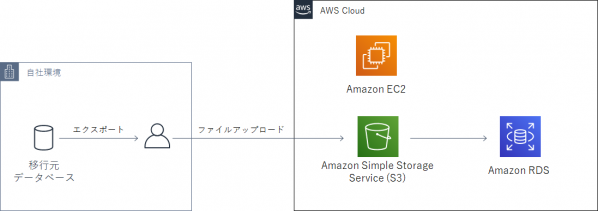
移行データはスキーマを指定しData Pumpで事前にエクスポートしています。
また、以下の環境は構築済みとします。
・EC2(操作用インスタンス)
OS:Windows 2012 R2
ソフトウェア:Oracle Database Client 12.2.0.1
・RDS
DBエンジン:Oracle Database Standard Edition Two
DBエンジンのバージョン:Oracle 12.2.0.1
オプショングループ:DBエンジンのバージョンに対応したものを作成
セキュリティグループ:操作用インスタンスからsqlplusでのアクセスを許可する
大まかな作業の流れ
作業前に大まかな流れを説明しておきます。
- S3の設定
データファイルを置くためのバケットを作成し、端末等からデータファイルをアップロードします。 - AWS Identity and Access Management (以下IAM)の設定
RDSから作成したバケットにアクセスするためのIAMポリシーとロール設定を行います。 - RDSの設定
作成したロールをRDSに割り当て、S3からファイルをダウンロードする機能(Amazon S3統合機能)を有効にします。 - RDSからS3のデータファイルをダウンロード
Amazon S3統合機能を使用してRDSからS3のデータファイルをダウンロードします。 - インポート準備
RDSで移行先データベースの設定を行います。 - Data Pumpでデータベースにインポート
RDSでData Pumpを使用し、データファイルをインポートします。
設定手順
S3の設定
移行データを格納するためのS3設定を行います。
・S3にバケットを作成します
・バケット内にData Pumpでエクスポートしたファイルのみをアップロードしておきます
IAMの設定
ポリシー作成
RDSがS3にアクセスする為に必要なポリシーを作成します。
・IAM管理画面で「ポリシー」をクリックし、「ポリシーの作成」ボタンをクリックします
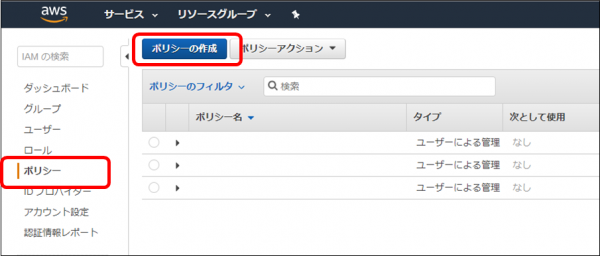
・「サービスの選択」をクリックします
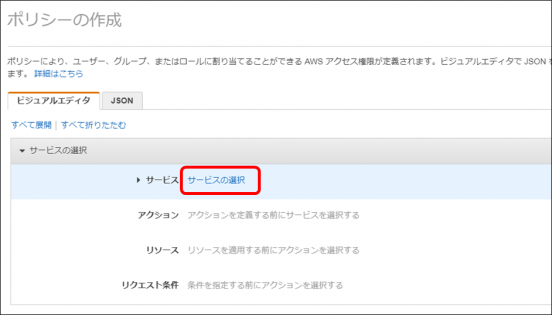
・「S3」をクリックします
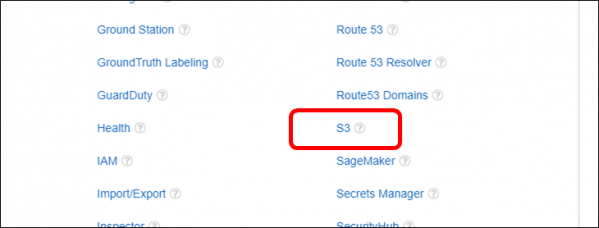
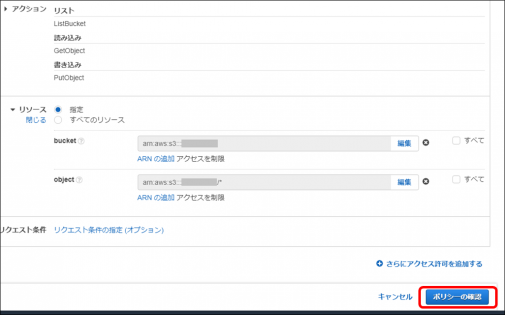
・「アクション」-「アクセスレベル」-「リスト」を開き、「ListBucket」を選択します
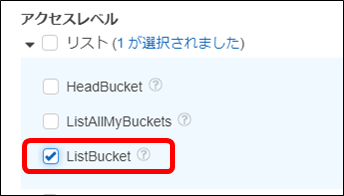
・「アクション」-「アクセスレベル」-「読み込み」を開き、「GetObject」を選択します
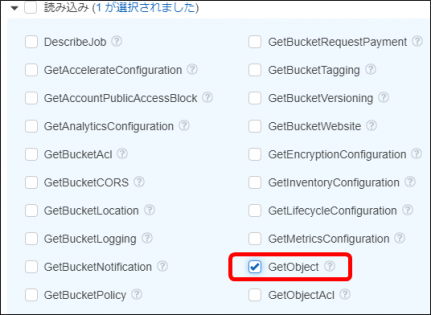
・「アクション」-「アクセスレベル」-「書き込み」を開き、「PutObject」を選択します
・「リソース」を開き、「bucket」行の「ARNの追加」をクリックします
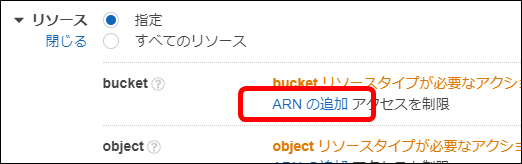
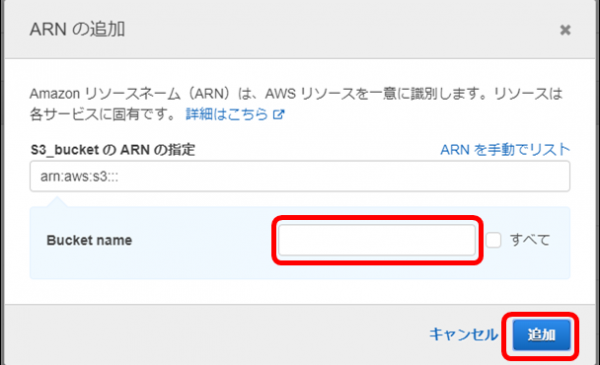
・「Bucket name」に作成しておいたバケット名を入力し、「追加」ボタンをクリックします
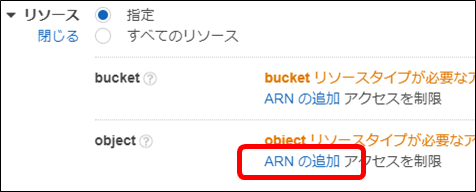
・「object」行の「ARNの追加」をクリックします
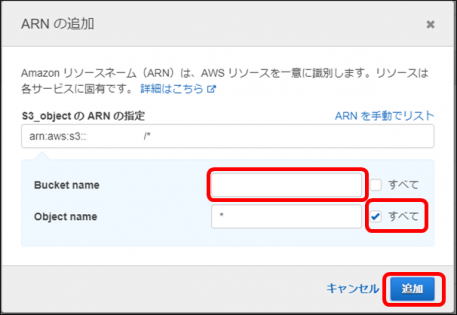
・「Bucket name」に作成しておいたバケット名を入力、「Object name」には何も入力せず、右端のチェックボックスをオンにして「追加」をクリックします
・「ポリシーの確認」をクリックします
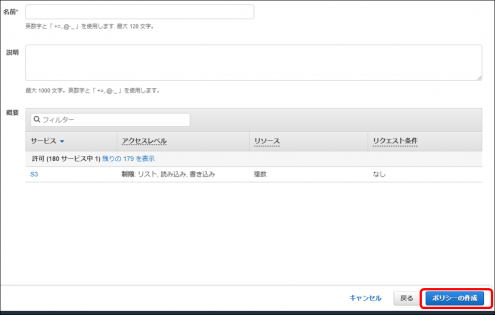
・ポリシー名を入力し「ポリシーの作成」をクリックします
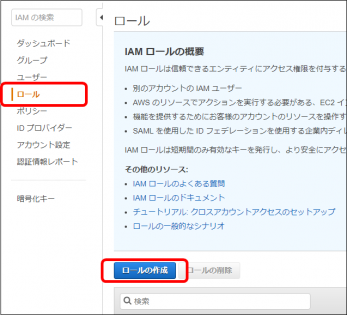
ロール作成
RDSがS3にアクセスする為に割り当てるロールを作成します。
・IAM管理画面で「ロール」をクリックし、「ロールの作成」ボタンをクリックします
・「このロールを使用するサービスを選択」で「RDS」をクリックします
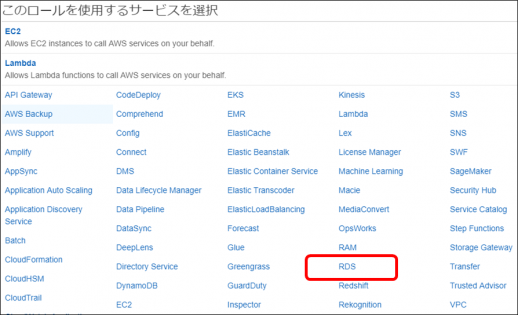
・画面下に「ユースケースの選択」が表示されるので、「RDS – Add Role to Database」をクリックし、「次のステップ:アクセス権限」ボタンをクリックします
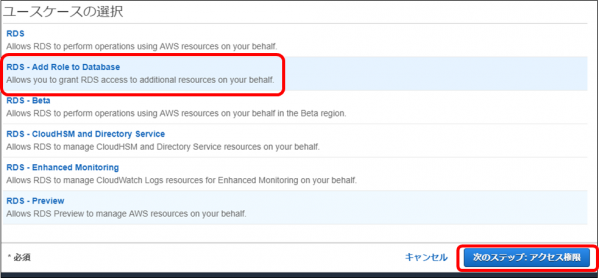
・作成したポリシーを選択し「次のステップ:タグ」をクリックします
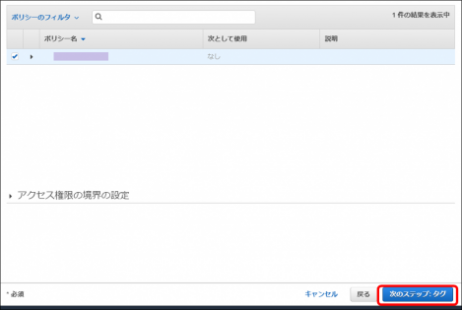
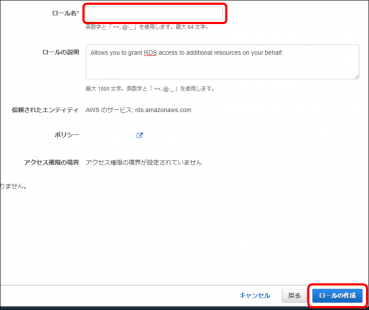
・(任意)タグを追加し「次のステップ:確認」をクリックします
・ロール名を入力し「ロールの作成」をクリックします
RDSの設定
オプショングループの設定
RDSからS3のファイルをダウンロードする機能を有効にします。
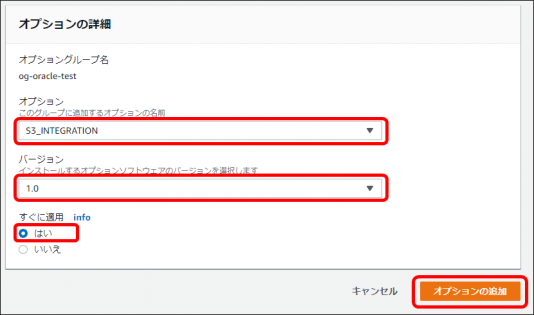
・RDS管理画面で「オプショングループ」をクリックし、データベースに割り当てているオプショングループのチェックボックスをオンにし、「オプションの追加」をクリックします
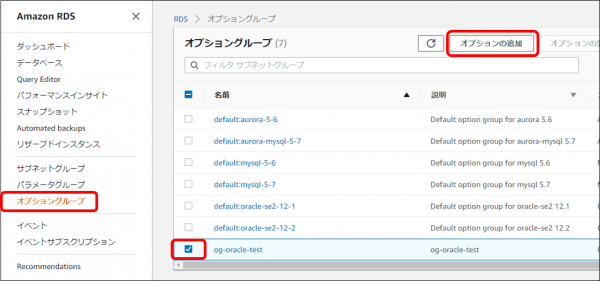
・「オプション」で「S3_INTEGRATION」、「バージョン」は「1.0」、「すぐに適用」は「はい」を選択し「オプションの追加」をクリックします
・データベースのステータスが「変更中」から「利用可能」になった事を確認します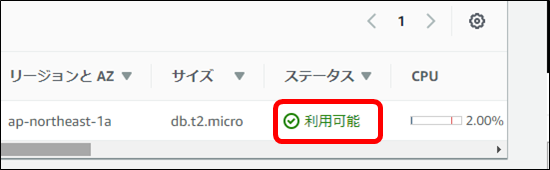
IAMロールの割り当て
RDSにIAMロールを割り当てます。
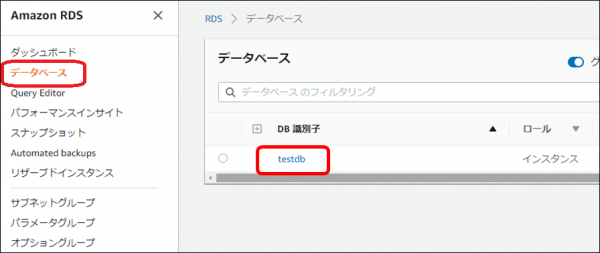
・RDS管理画面で「データベース」をクリックし、対象データベースをクリックします
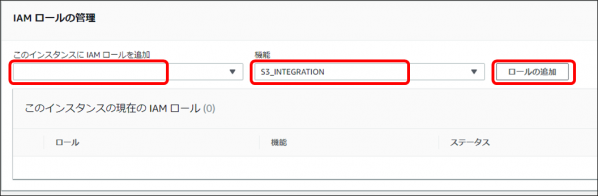
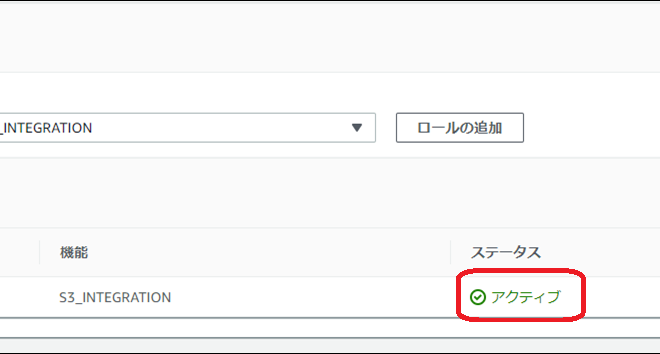
・画面最下部の「IAMロールの管理」で、「このインスタンスに IAM ロールを追加」で作成したロール、「機能」で「S3_INTEGRATION」を選択し、「ロールの追加」をクリックします
・「ステータス」が「保留」から「アクティブ」になった事を確認します
・データベースのステータスが「変更中」から「利用可能」になった事を確認します
RDSからS3のデータファイルをダウンロード
・操作用インスタンスでコマンドプロンプトを起動し、sqlplusを使用してRDSに接続します
|
1 |
sqlplus マスターユーザー名/マスターパスワード@(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=エンドポイント)(PORT=1521))(CONNECT_DATA=(SID=ORCL))) |
・ファイルが格納されるDATA_PUMP_DIR配下のファイルを確認します
|
1 |
select * from table (rdsadmin.rds_file_util.listdir(p_directory => 'DATA_PUMP_DIR')); |
・RDSからS3のデータファイルをダウンロードします
|
1 |
select rdsadmin.rdsadmin_s3_tasks.download_from_s3(p_bucket_name => 'バケット名', p_directory_name => 'DATA_PUMP_DIR') AS TASK_ID FROM DUAL; |
コマンドに間違いがなければTASK IDが返されます
|
1 2 3 |
TASK_ID -------------------------------------------------------------------------------- 1559639797887-38 |
・実行ログを確認します
前の手順で取得したTASK IDを使用して実行ログファイル名を指定し、実行ログを表示させます
|
1 |
select text from table(rdsadmin.rds_file_util.read_text_file('BDUMP','dbtask-1559639797887-38.log')); |
”The task finished successfully”と表示されていればデータファイルのダウンロードは成功しています
|
1 2 3 4 |
S3 object or objects from bucket name バケット名 with key EXPORT.DMP to the lo cation /rdsdbdata/datapump. 2019-06-04 09:16:59.698 UTC [INFO ] The task finished successfully. |
インポート準備
・スキーマ作成します
|
1 |
CREATE USER TS_USR IDENTIFIED BY パスワード; |
・表領域の作成します
|
1 |
CREATE TABLESPACE 表領域名 DATAFILE SIZE 1G AUTOEXTEND ON NEXT 100M MAXSIZE UNLIMITED; |
・デフォルトのテーブルスペースを変更します
|
1 |
ALTER USER ユーザー名 DEFAULT TABLESPACE 表領域名 TEMPORARY TABLESPACE TEMP; |
・必要な権限付与を行います
|
1 2 3 4 |
GRANT CONNECT, RESOURCE TO ユーザー名; ALTER USER ユーザー名 QUOTA UNLIMITED ON USERS; GRANT UNLIMITED TABLESPACE TO ユーザー名; GRANT read,write on directory DATA_PUMP_DIR to ユーザー名; |
Data Pumpでデータベースにインポート
・Data Pumpを実行します
実行ログを”IMPORT.LOG”に指定しています。
|
1 2 3 4 5 6 7 8 9 10 |
DECLARE hdnl NUMBER; BEGIN hdnl := DBMS_DATAPUMP.open(operation=>'IMPORT', job_mode=>'SCHEMA', remote_link=>null, job_name=>null, version=>'COMPATIBLE'); DBMS_DATAPUMP.ADD_FILE(handle=>hdnl, filename=>'EXPORT.DMP', directory=>'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_dump_file); DBMS_DATAPUMP.ADD_FILE(handle=>hdnl, filename=>'IMPORT.LOG', directory => 'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_log_file); DBMS_DATAPUMP.METADATA_FILTER(hdnl,'SCHEMA_EXPR','IN (''スキーマ名'')'); DBMS_DATAPUMP.start_job(hdnl); END; / |
・Data Pumpの実行ログを確認します
|
1 |
SELECT TEXT FROM TABLE(RDSADMIN.RDS_FILE_UTIL.READ_TEXT_FILE('DATA_PUMP_DIR','IMPORT.LOG')); |
”successfully completed”が表示されていればインポートは成功しています
|
1 2 3 4 |
TEXT -------------------------------------------------------------------------------- Job マスターユーザー名."SYS_IMPORT_SCHEMA_01" successfully completed at Tue Jun 4 18:23:3 3 2019 elapsed 0 00:03:54 |
・データファイルと実行ログファイルを削除します
|
1 2 |
exec utl_file.fremove('DATA_PUMP_DIR','EXPORT.DMP'); exec utl_file.fremove('DATA_PUMP_DIR','IMPORT.LOG'); |
おわりに
今回はタイミングよく新機能を利用し、スムーズに移行することができました。クラウド界隈は技術の進歩が速いので、最新技術のキャッチアップは非常に重要だと改めて感じさせられました。

執筆者プロフィール

- tdi デジタルイノベーション技術部
- 福岡県在住。半導体関連、アプリケーション開発、運用関連業務を経て、現在はインフラ系の技術支援業務を担当。直近のテーマはクラウド技術者育成と体力づくり。
この執筆者の最新記事
 AWS・クラウド2019年7月10日Amazon S3を利用したAmazon RDS for Oracleへのデータ移行
AWS・クラウド2019年7月10日Amazon S3を利用したAmazon RDS for Oracleへのデータ移行 AWS・クラウド2019年2月25日Amazon WorkMailを使って独自ドメインのメールサービスを構築してみた
AWS・クラウド2019年2月25日Amazon WorkMailを使って独自ドメインのメールサービスを構築してみた AWS・クラウド2018年9月14日Amazon EFSを試してみました
AWS・クラウド2018年9月14日Amazon EFSを試してみました